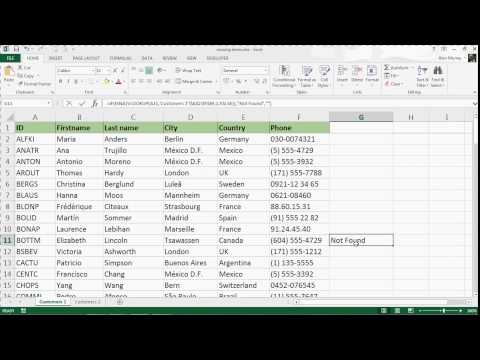
To Select random rows or selecting random records on SAP HANA database table, SQLScript developers can use SQL functions just like in other databases. Another requirement is to order or sort a set of rows randomly. If you are working on data warehouse or any database query then you might have received the request to get random numbers based on on some key columns. In this article, we will check Netezza select random rows in nzsql and explanation with an examples. Sometimes you may need to pick random rows from your database table, for the purpose of inspection or displaying on your website. For example, you may want to show random blog posts or images on your website.

In MySQL, there is no built-in function to select random records. In this article, we will look at how to select random records in MySQL. If you're new to the big data world and also migrating from tools like Google Analytics or Mixpanel for your web analytics, you probably noticed performance differences.

Google Analytics can show you predefined reports in seconds, while the same query for the same data in your data warehouse can take several minutes or even more. Such performance boosts are achieved by selecting random rows or thesampling technique. In addition to the TableSample clause, within the returned list, you can sort rows using Rand() random function and select top 3 rows only, for example. But since you might have less rows than expected from the table sampling functions , it is not a convenient method of selected specific number of random rows from a database table. In this video I help you solve the dual problems of selecting a random value from an Excel list and selecting a number of random rows from a range of data in Excel. At times when I am generating a data-set to use in my video tutorials, I want to select a random selection of rows.

Typically, because my data values are clumped together and are too similar to the data on preceding and subsequent rows. The above syntax select random rows only from the specified columns. You just have to enter the column names from which you want to retrieve random rows and the table name from where you want to retrieve the random rows of specified columns. Performance boosts are achieved by selecting random rows or the sampling technique.
Below is the query that can be used to select random rows in Netezza. Sometimes our table contains large number of records where we need to retrieve some of them . The TABLESAMPLE clause in SQL Server allows to extract a sampling of rows from a table in the FROM clause. It limits the number of rows returned from a table in the FORM clause to a sample number or PERCENT of rows.

The TABLESAMPLE clause takes a parameter that can be a percent or a number representing how many rows to retrieve. The retrieved result of rows are random and they are not in any order. Each time you get a different result set when you run query. This tutorial illustrates how to select random rows in a data frame in the R programming language. A while ago, we described a few different ways to randomly select in Excel.

Most of those solutions rely on the RAND and RANDBETWEEN functions, which may generate duplicate numbers. Consequently, your random sample might contain repeating values. If you need a random selection without duplicates, then use the approaches described in this tutorial. The weird part is that the given number might not match the number of rows of your result.

You might got more or less results and if our tablesample is too small you might even got nothing in return. There are some clever ways to work around this (e.g. using the TOP 100 statement with a much larger tablesample clause to get a guaranteed result set), but it feels "strange". If you hit limitations with the first solution you might want to read more on this blog or in the Microsoft Docs. In SQL Server, it is quite easy to do this thanks to the NEWID() system function.
The NEWID() system function creates a unique value of type uniqueidentifier. There's no need to add a new column to your table just to have the ability of randomly selecting records from your table. All that needs to be done is include the NEWID() system function in the ORDER BY clause when doing your SELECT statement. When you run the above code every single time you will see a different set of 10 rows. The trick is to add ORDER BY NEWID() to any query and SQL Server will retrieve random rows from that particular table.

Additionally, they wanted to make sure that whatever the row they select ones, the same set of rows should not be selected next time and the rows should be truly random. For example, you can be interested in some rare event count such as an enterprise demo request being some B2C site with a huge amount of traffic. Generally speaking, sampling random rows in SQL should be avoided in this case ormore sophisticated methodsshould be used instead. As a developer, if you are interested to work with a randomly selected sample data from a database table, SQLScript provides TABLESAMPLE clause in SELECT statement syntax. Honestly, it is possible to retrieve random rows from any tables. Let us see a simple example on the AdventureWorks database.

Let's discuss how to randomly select rows from Pandas DataFrame. A random selection of rows from a DataFrame can be achieved in different ways. Learn how to use SQL SELECT RANDOW rows from a table with the tutorial and Examples. Find out how to retrieve random rows in a table with SQL SELECT RANDOM statement.

We can use the RAND() function in conjunction with an ORDER BY clause and the LIMIT keyword to return random rows from that table. You can use the RAND() function to select random records from a table in MySQL. In this tutorial you will learn how to retrieve a set of random records from a database table in MySQL, Oracle and Microsoft SQL Server. You'll also learn how to retrieve random documents from a collection in MongoDB database. Simple random sampling can be implemented as giving a unique number to each user in a range from 0 to N-1 and then selecting X random numbers from 0 to N-1.

N denotes the total number of users here and X is the sample size. Also it isn't very clear as to how to get evenly distributed samples over time. There are manysyntaxes given below to get random rows from the table. Many developers using it for exam websites to retrieving random questions from the database. You can use either ROWS or PERCENT to specify how many rows you want back in the results.

SQL Server generates a random value for each physical page in that table. Based on that value, the page is either included or excluded. When a page is included, all rows in that page are included. For example, if you choose to select only 5 percent, then all rows from approximately 5 percent of the data pages are included in the result.

When you choose the number of rows explicitly as in the previous example, this number is actually converted into a percentage of the total number of rows in that table. Because page size can vary, you might not get the exact number of rows you requested. Rather, you will get a result set size close to the number you requested. Let's demonstrate random selection of table records with a few RAND() function SQLScript samples. Then we do an Inner Join between the original table and the result of above subquery to get a table of random rows. Finally, we use LIMIT clause to filter only required random rows.

In Oracle, the VALUE function in DBMS_RANDOM package returns a random number between 0 and 1 which can be combined with ORDER BY and FETCH clauses to return random rows. Sometimes there is a need to fetch random record from the table. In this tutorial, we will see how to select a random record from a table using RAND function. This SQL query and all SQL queries below are in Standard BigQuery SQL. In this example, we're selecting one user out of 10, which is a 10% sample. 7 is the random number of the sampling bucket and it can be any number from 0 to 9.

We use MOD operation to create sampling buckets which stand for the remainder of a division by 10 in this particular case. It's really simple to show that ifuser_idis a strict integer sequence, then user counts are uniformly distributed across all sampling buckets when user count is high enough. From the randomly sorted data, you extract a sample of a specific size. Because the original data is already sorted in random order, we do not really care which positions to retrieve, only the quantity matters. Get the random rows from postgresql using RANDOM() function.

CodeThe random row selection in SQL Server can be accomplished by sorting the table with ORDER BY NewID() clause. Another option can be using the SQLScript TABLESAMPLE clause to select randomly choosen rows from a dataset. 44127In addition to randomly retrieving data you can all use the REPEATABLE option so that the query returns the same random set of data each time you run the query. Every day I spend a good amount of time with different customers helping them with SQL Server Performance Tuning issues. Today we will discuss the question asked by a developer at the organization where I was engaged inComprehensive Database Performance Health Check. The developers wanted to know if there is any way he can randomly select n rows from a table.

The above query works well with small tables but it will slow down as the number of rows increase. This is because MySQL has to sort the entire table before picking the random rows. Alternatively, you can check the following guide to learn how to randomly select columns from Pandas DataFrame. The goal is to randomly select rows from the above DataFrame across the 4 scenarios below.

To get random questions, you need to use the rand() in SQL SELECT random rows statement. Use TABLESAMPLE on large tables and when the resulting rows do not have to be truly random at the level of individual rows. However, TABLESAMPLE cannot be applied to derived tables, tables from linked servers, and tables derived from table-valued functions, rowset functions, or OPENXML.

TABLESAMPLE cannot be specified in the definition of a view or an inline table-valued function. When using this technique, MariaDB reads all rows in the table, generates a random value for each of them, orders them, and finally applies the LIMIT clause. Here's a quick way to return random rows from a table in MariaDB.
In the following, I'll show you how to sample some rows of this data frame randomly. TableSample clause returns a random sample of the table data. The way this works is that data is read at a page level.
So based on this, each run can retrieve a totally different number of rows of data. In the above query, RAND() function generates random value for each row in table. ORDER BY sorts the rows based on this random number generated for each row. LIMIT clause filters the result to the number of rows you want. Be careful because TableSample doesn't actually return a random sample of rows. It directs your query to look at a random sample of the 8KB pages that make up your row.

Then, your query is executed against the data contained in these pages. Because of how data may be grouped on these pages , this could lead to data that isn't actually a random sample. This can be largely remedied by a hybrid query, by mixing sampling and ORDER BY selection from the much smaller sample set.

This limits the sorting operation to the sample size, not the size of the original table. This works with holes in the table data, as long as you have an index to work with for the ORDER BY clause. Its also very good for the randomness - as you work that out yourself to pass in but the niggles in other methods are not present. In addition the performance is pretty good, on a smaller dataset it holds up well, though I've not tried serious performance tests against several million rows. Probably has nothing to do with mathematical random selection from resultset, but it look like it is ...
I've used various methods for selecting random records (RAND(), TABLESAMPLE BERNOULLI(), TABLESAMPLE SYSTEM()), but those don't have the weighting that I'm after. The above query returns approximately 10 percent of total rows present in that table. The number of rows returned usually changes every time that the statement is executed. The system_rows version of the TABLESAMPLE function will pick a random disk block in the table, and then fetch rows sequentially from there. Picking a random block can be done by just looking at the size of the table so this is very very fast. TABLESAMPLE is a functionality designed to return a sample portion of a table, such as 10%.

But with the plugin tsm_system_rows , we can get a sample number of rows back. The performance of the scan is not entirely independent of the size of the table but almost, and even on very large tables it runs extremely fast if you just need a row. And while Jonathan's method is still about twice as fast as ORDER BY random() on my test , it comes with some problems.
For example, it requires a contiguous set of id values, that have to be integers. And it still takes about a second to run on my machine with his sample of 5 million rows – and will keep getting slower as the table grows. At first glance this sounds great, but there are a few things to keep in mind when using this new option. In MS SQL Server, the NEWID() function assigns a unique random value to each row in the table and the ORDER BY clause sorts the records. The RAND() function generates a random number between 0 and 1 for each row in the table and the ORDER BY clause will order the rows by their random number. Such a sampling approach is less efficient than the first code shown and is error-prone if the goal is to find a "single random row".

This article also explains you on Netezza select random samples that you may use in other client related applications. Not all hash functions can get you uniform distribution under different circumstances. You can checksmhashertest suite results to check how good a particular hash function is at this. Bearing this in mind, we'll use systematic sampling which can overcome these obstacles from an SQL implementation perspective. Simple systematic sampling may be implemented as selecting one user from each M users at a specified interval. Selecting one user out of M while preserving uniform distribution across sample buckets is the main challenge of this approach.
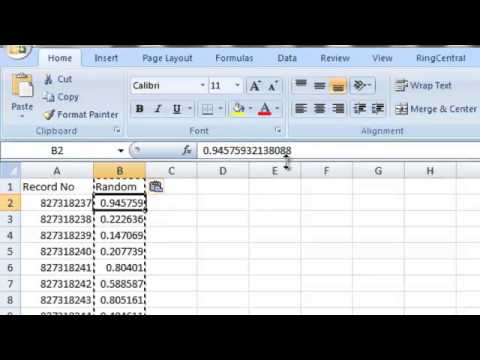
By placing the RAND() function in a column co-located with your data, you will assign a random number to each row in your data-set or range. Running it over and over again generated the same result set. If the RAND() system function is supposed to generate random numbers when executed, how come the result set generated are all the same? To investigate this further, let's include the result of the RAND() system function as part of the result set. If you fetch more rows than was on that page, PostgreSQL will pick another random block. So you will get sets of sequential rows, but the sets themselves are random.


No comments:
Post a Comment
Note: Only a member of this blog may post a comment.